安装scrapy
因为用的是anaconda,所以直接pip install scrapy就成功了。如果不成功可以pip install lxml先,可以查看下版本
scrapy --version
Scrapy 1.7.1 - project: tutorial
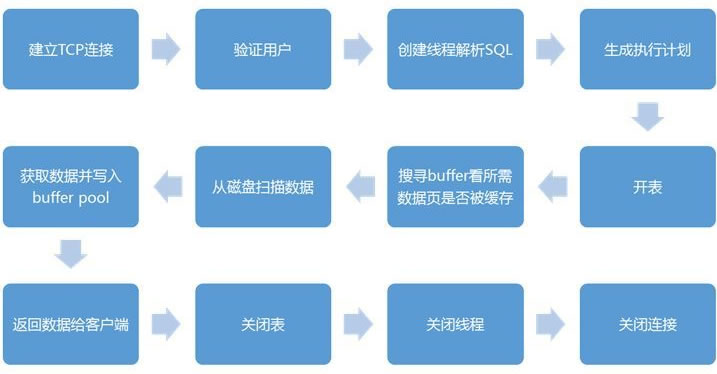
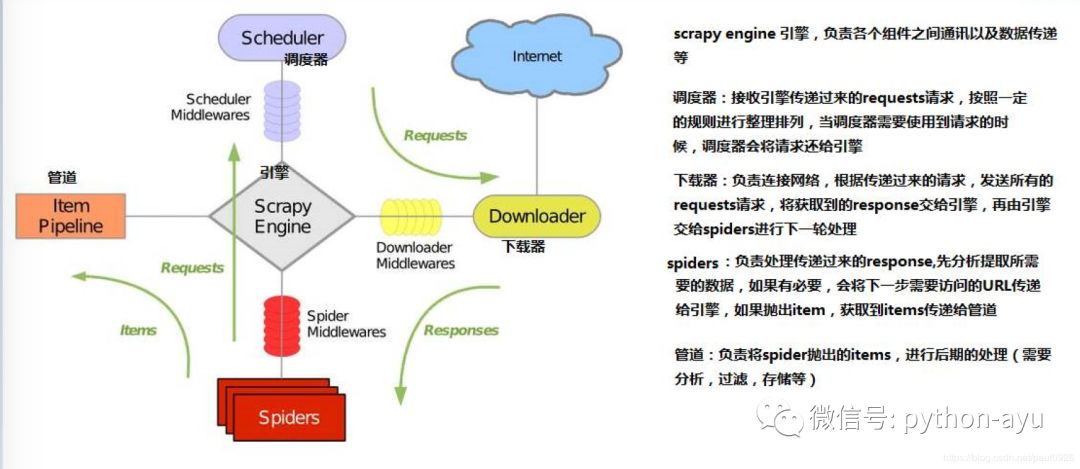
scrapy组件和流程

一个简单的项目实例(爬猫眼电影排行)
用终端创建,cd到你放scrapy项目的文件夹,然后开始项目maoyan是你的项目名,自己取名
nginx">scrapy startproject maoyan
项目结构
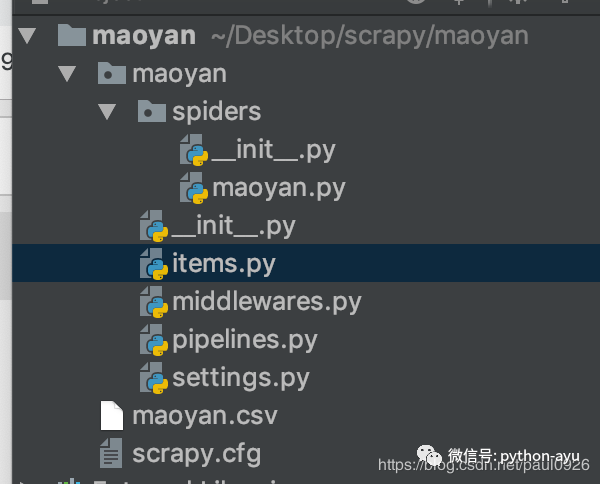
文件 功能
scrapy.cfg 配置文件
spiders 存放你Spider文件,也就是你爬取的py文件
items.py文件 相当于一个容器,和字典较像
middlewares.py文件 定义Downloader Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现
pipelines.py文件 定义Item Pipeline的实现,实现数据的清洗,储存,验证。
settings.py文件 全局配置
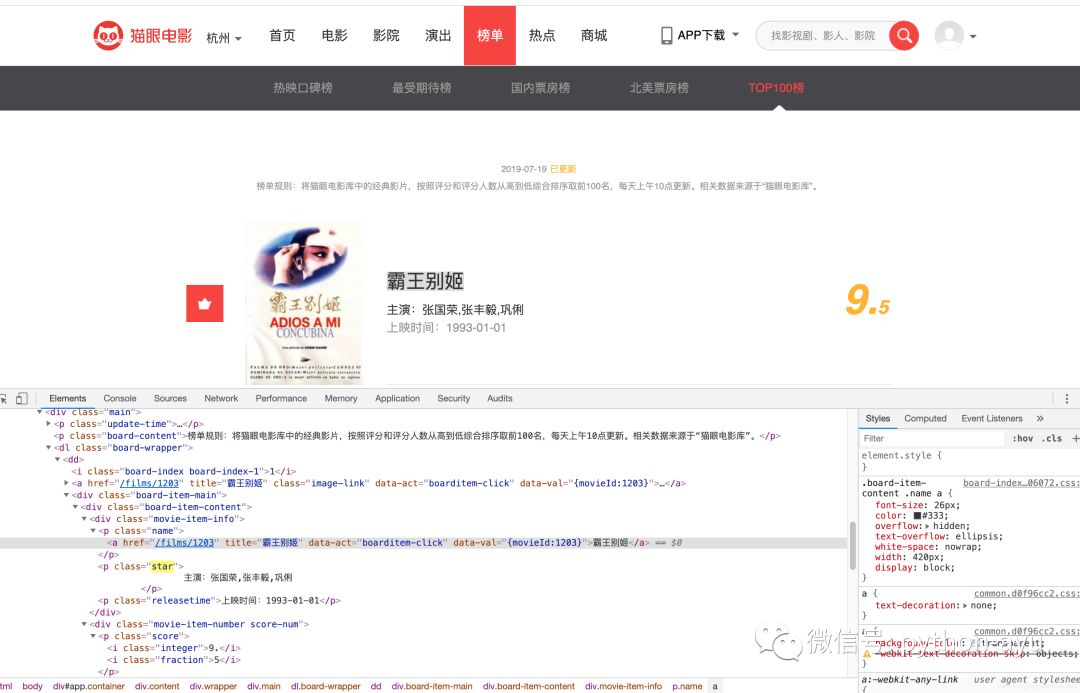
分析要爬取的网页和内容
要爬取的网址是’https://maoyan.com/board/4?offset=0’ 然后往后的十个网页,写成列表
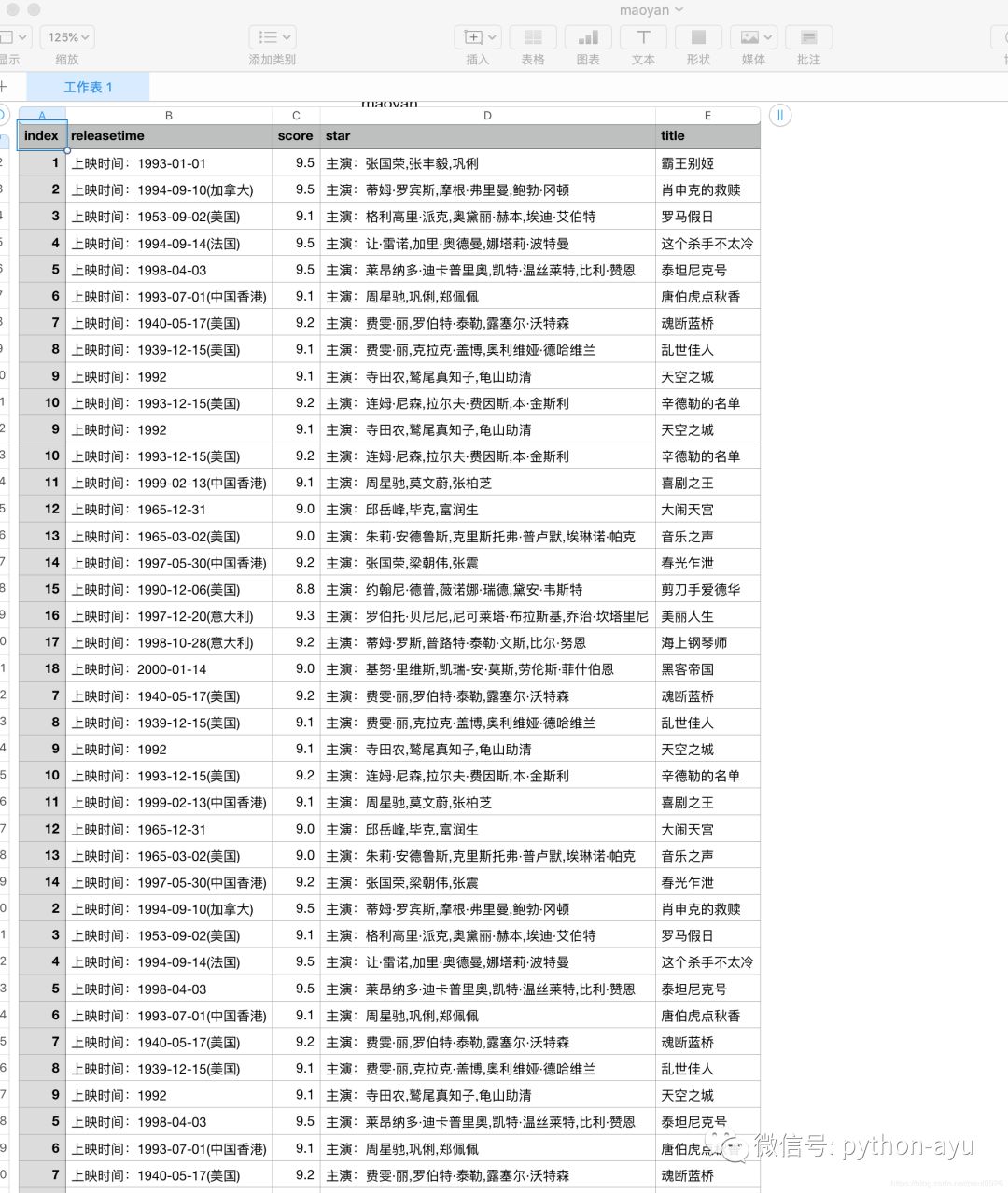
然后是要爬取的内容:电影名、评分、主演等
创建一个spider
属性或方法 作用
name 是项目的名字
allowed_domains 是允许爬取的域名,比如一些网站有相关链接,域名就和本网站不同,这些就会忽略。
start_urls 要访问的地址列表,和start_requests方法只需要定义一个,都是调用parse方法解析
start_requests方法 由此方法通过下面链接爬取页面
parse方法 是Spider的一个方法,在请求start_url后,之后的方法,这个方法是对网页的解析,与提取自己想要的东西。
response参数 是请求网页后返回的内容,也就是你需要解析的网页。
python">import scrapy
class MySpider(scrapy.Spider):
name = 'maoyan' # 项目名
allowed_domains = ['maoyan.com'] # 允许访问的域名
def start_requests(self):
url_list = []
for i in range(0,10):
url_list.append('https://maoyan.com/board/4?offset='+str(i))
# 定义爬取的链接
urls = url_list
for url in urls:
# 爬取到的页面如何处理?提交给parse方法处理
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
pass
定义需要的item
item是保存爬取数据的容器,使用的方法和字典差不多。
我们打开items.py文件,之后我们想要提取的信息有:
index(排名)、title(电影名)、star(主演)、releasetime(上映时间)、score(评分)
class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
index = scrapy.Field()
title = scrapy.Field()
star = scrapy.Field()
releasetime = scrapy.Field()
score = scrapy.Field()
然后修改spider的方法来获取信息
python">from maoyan.items import MaoyanItem
...
def parse(self, response):
'''
start_requests已经爬取到页面,那如何提取我们想要的内容呢?那就可以在这个方法里面定义。
1、定义链接;
2、通过链接爬取(下载)页面;
3、定义规则,然后提取数据;
'''
# 这里用的css选择查找信息,也可以用xpath
dl = response.css('.board-wrapper dd')
for dd in dl:
item = MaoyanItem()
# extract()[0]等同于extract_first()
item['index'] = dd.css('.board-index::text').extract_first()
item['title'] = dd.css('.name a::text').extract_first()
# strip方法是去除空格和换行符
item['star'] = dd.css('.star::text').extract_first().strip()
item['releasetime'] = dd.css('.releasetime::text').extract_first()
item['score'] = dd.css('.integer::text').extract_first()+dd.css('.fraction::text').extract_first()
yield item
...
运行并保存
这样就写完了一个简单的项目,运行即可:
在终端的当前文件夹下输入:scrapy crawl maoyan(项目的名字)
这样只运行了代码,并没有保存,保存有多种方式
-o maoyan.csv或者-o maoyan.xml或者-o maoyan.json
设置编码格式 -s FEED_EXPORT_ENCODING=UTF8
选择csv(表格)格式保存看看:scrapy crawl maoyan -o maoyan.csv -s FEED_EXPORT_ENCODING=UTF8
找到文件并打开: