JS 基础: RegExp 正则表达式完整理解与应用
文章目录
前言
揪着正则表达式很久了,一直没来看看。前段时间面试的时候被问到跟正则表达式有关的题目;解析 Vue2 源码的时候,也在模版编译的部分看到了正则表达式的应用,今天终于要来带大家好好地过一遍正则表达式的所有能力!
正文
0. 什么是正则表达式?
所谓的 正则表达式(Regular Expression) 实际上是一种 对于字符串的描述模式。简单来说,就是透过一些符号的组合来表示一些字符串的集合。
1. JS 中与正则表达式相关的方法
在开始介绍之前,我们先来说说几个 JS 中关于正则表达式会用到的方法,到目前为止我们只需要知道正则表达式就是一种对于字符串特征的描述即可
1.0 JS 中正则表达式的构造方法:字面量、RegExp 构造函数
首先是正则表达式的创建。在 JS 的语言标准中,多数环境都会内置 RegExp 也就是正则表达式的类型。
当我们要创建一个正则表达式 RegExp 类型的时候,我们可以采取两种方法
/src/basic.js
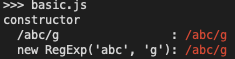
js">group('constructor', () => {
log(`/abc/g :`, regex">regex-delimiter">/regex-source language-regex">abcregex-delimiter">/regex-flags">g)
log(`new RegExp('abc', 'g'):`, new RegExp('abc', 'g'))
})
在 JS 中我们可以使用
- 正则表达式的字面量形式
/pattern/modifier:使用两个/符号作区隔,第一个空位为表达式本身,而第二部分则是正则表达式的匹配模式,后面我们会再说明有哪些模式、分别由那些作用 RegExp构造函数形式new RegExp(pattern, modifier):一样第一个参数为表达式的字符串,第二个参数是匹配模式
下面我们看看到底这个类型要怎么用
1.1 RegExp.prototype.test(string)
第一个是 test 方法,用于 验证参数字符串是否匹配该正则表达式
/src/methods.js
js">group('RegExp.prototype.test(string)', () => {
const reg_a = regex">regex-delimiter">/regex-source language-regex">^aregex-delimiter">/
log('reg_a:', reg_a)
log(`reg_a.test('12345'):`, reg_a.test('12345'))
log(`reg_a.test('12a45'):`, reg_a.test('12a45'))
log(`reg_a.test('a1245'):`, reg_a.test('a1245'))
})
这里的 /^a/ 表示以 a 字符开头的意思,所以实际上应该只有第三个为 true 我们看看结果

1.2 RegExp.prototype.exec(string)
第二个方法 exec 是 获取表达式匹配的字符串和详细信息
正则表达式常常只是对于字符串的描述,所以并不一定是普通的字符串,所以我们很多时候在匹配之后除了检查字符串是否匹配之外,还会想顺便获取表达式对应的实际字符串
/src/methods.js
js">group('RegExp.prototype.exec(string)', () => {
const reg_a = regex">regex-delimiter">/regex-source language-regex">^aregex-delimiter">/
log('reg_a:', reg_a)
log(`reg_a.exec('12345'):`, reg_a.exec('12345'))
log(`reg_a.exec('12a45'):`, reg_a.exec('12a45'))
log(`reg_a.exec('a1245'):`, reg_a.exec('a1245'))
})

上面的表达式一样只有第三个字符串符合,所以前两个会返回 null 而第三个会返回匹配信息的描述(后面学习更多应用的时候会再详细说明这个返回值的含义)
regexp_92">1.3 String.prototype.match(regexp)
match 方法就好比是 exec 方法的对调,只是从 regexp.exec(string) 变成 string.match(regexp),方法含义与返回值是一致的
/src/methods.js
js">group('String.prototype.match(regexp)', () => {
log(`'12345'.match(/^a/) :`, '12345'.match(regex">regex-delimiter">/regex-source language-regex">^aregex-delimiter">/))
log(`'12a45'.match(/^a/) :`, '12a45'.match(regex">regex-delimiter">/regex-source language-regex">^aregex-delimiter">/))
log(`'a1245'.match(/^a/) :`, 'a1245'.match(regex">regex-delimiter">/regex-source language-regex">^aregex-delimiter">/))
log(`'a1245'.match('^a') :`, '1^a45'.match('^a'))
log(`'a1245'.match('^a.') :`, 'a1245'.match('^a.'))
log(`'a.245'.match('^a\\.'):`, 'a.245'.match('^a\\.'))
})

这边需要注意的是参数传入的如果是字符串,是会被当成表示正则表达式的字符串来解析,如第五个例子:. 符号在正则表达式中匹配任意字符,所以结果是 ‘a1’;而第六个例子的意义则是 \\ 为 JS 字符串对 \ 符号的转译,\. 在正则表达式中才是对 . 的转义
regexp_113">1.4 String.prototype.search(regexp)
除了匹配之外,我们还可以使用 search 方法查找 符合表达式的字符串的起始下标
/src/methods.js
js">group('String.prototype.search(regexp | string)', () => {
log(`'12345'.search(/a/):`, '12345'.search(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/))
log(`'12a45'.search(/a/):`, '12a45'.search(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/))
log(`'a1245'.search(/a/):`, 'a1245'.search(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/))
})
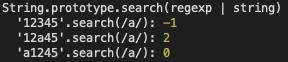
第一个例子不存在符合条件的字符串,则返回 -1;第二、三个例子则是返回 a 字符的起始下标
regexp_string__Function_131">1.5 String.prototype.replace(regexp, string | Function)
下一个方法则是 replace 方法,除了查找匹配字符串之外,还传入第二个参数用以 替换第一个参数所匹配到的字符串
/src/methods.js
js">group('String.prototype.replace(regexp | string, string)', () => {
log(`'12345'.replace(/a/, 'xxx'):`, '12345'.replace(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/, 'xxx'))
log(`'12a45'.replace(/a/, 'xxx'):`, '12a45'.replace(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/, 'xxx'))
log(`'a1245'.replace(/a/, 'xxx'):`, 'a1245'.replace(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/, 'xxx'))
})

第一个例子没有任何匹配的字符串,所以没有任何替换;二、三个例子则是将 xxx 替换到目标位置
regexp_149">1.6 String.prototype.split(regexp)
最后一个则是根据参数表达式 对原字符串进行分割
/src/methods.js
js">group('String.prototype.split(regexp | string)', () => {
log(`'12345'.split(/a/):`, '12345'.split(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/))
log(`'12a45'.split(/a/):`, '12a45'.split(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/))
log(`'a1245'.split(/a/):`, 'a1245'.split(regex">regex-delimiter">/regex-source language-regex">aregex-delimiter">/))
})
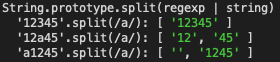
需要注意的是当他匹配的在最前头的时候会分离出一个 '' 空串
2. 正则表达式基础
介绍了一遍 JS 语言中与正则表达式相关的方法,接下来我们就回到正则表达式的核心内容上
2.0 正则表达式完整规则表
首先我们先贴出一个正则表达式的全部规则大表,后面我们会一个个解释不同用法的作用
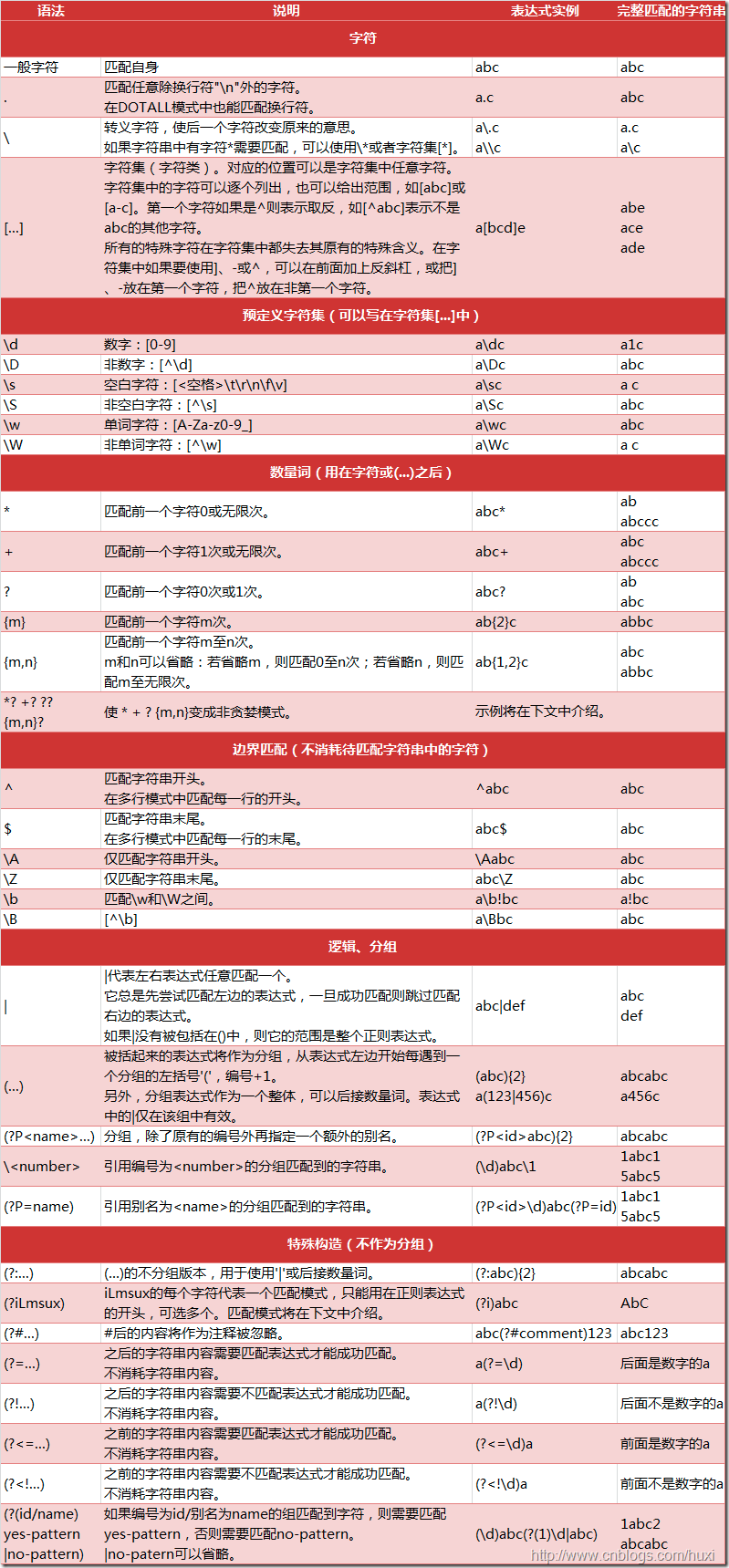
2.1 基本字符 & 特殊符号
我们第一个要解释的是基本字符和特殊符号,在正则表达式中对于一般符号实际上就是直接匹配原符号;而其他还存在一些特殊符号来代表一些不同 符号的集合
| 正则表达式符号 | 匹配字符 |
|---|---|
. | 匹配任意字符 |
\d | 匹配数字字符 |
\D | 匹配非数字字符 |
\s | 匹配空白字符 |
\S | 匹配非空白字符 |
\w | 匹配内容字符(大小写符号与数字) |
\W | 匹配非内容字符 |
同时不仅仅有代表字符集合的特殊字符,还有用于 描述位置的特殊字符
| 正则表达式符号 | 匹配字符 |
|---|---|
\b | 匹配单词边界 |
\B | 匹配非单词边界 |
^ | 匹配字符串开头 |
$ | 匹配字符串结尾 |
下面我们看看实践例子
/src/basic.js
js">group('characters', () => {
const str = 'abcdefghijklmnopqrstuvwxyz1234567890\t \0:?><!@#$%^&*()_+,./'
log(`str: ${str}`)
log(`str.match(/abc/):`, str.match(regex">regex-delimiter">/regex-source language-regex">abcregex-delimiter">/))
log(`str.match(/cde/):`, str.match(regex">regex-delimiter">/regex-source language-regex">cderegex-delimiter">/))
log(`str.match(/\\w+/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\w+regex-delimiter">/))
log(`str.match(/\\W+/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\W+regex-delimiter">/))
log(`str.match(/\\d+/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\d+regex-delimiter">/))
log(`str.match(/\\D+/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\D+regex-delimiter">/))
log(`str.match(/\\s+/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\s+regex-delimiter">/))
log(`str.match(/\\S+/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\S+regex-delimiter">/))
})
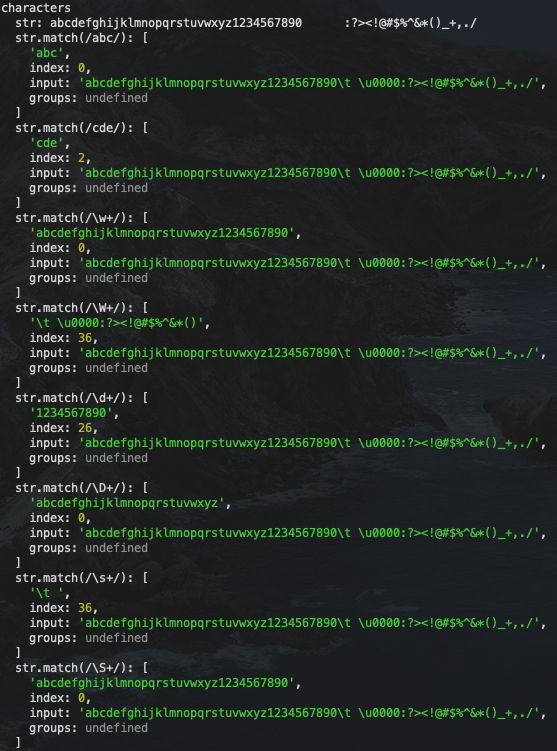
我们可以从结果看到不同特殊字符对于特殊字符的匹配结果
2.2 方括号:匹配指定符号 & 匹配非指定符号
能够使用特殊字符匹配字符集合中的单个字符之后,有时候我们又希望能自定义这样的字符集合,我们就要使用 [] 符号
| 正则表达式 | 含义 |
|---|---|
[abc] | 匹配 abc 其中一个字符 |
[0-9] | 匹配字符 0 到字符 9之间(按 ASCII 码比较)的所有字符 |
[^abc] | 匹配 abc 之外的任意字符 |
(abc\|def) | 匹配整个字符串 abc 或是 def |
/src/basic.js
js">group('options', () => {
const str = '1234567890'
log(`str: ${str}`)
log(`str.match(/123/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">123regex-delimiter">/))
log(`str.match(/[123]/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">[123]regex-delimiter">/))
log(`str.match(/[123]+/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">[123]+regex-delimiter">/))
log(`str.match(/[^123]/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">[^123]regex-delimiter">/))
log(`str.match(/[5-9]+/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">[5-9]+regex-delimiter">/))
log(`str.match(/(345|789)+/g):`, str.match(regex">regex-delimiter">/regex-source language-regex">(345|789)+regex-delimiter">/regex-flags">g))
})

备注:match 方法使用 g 描述符的时候不会返回匹配详细信息,而是返回所有符合条件的字符串数组
2.3 圆括号:分组 & 捕获
前面我们用到了 (|) 来做可选字符串集合,事实上 () 本身就代表了 匹配字符串的分组
/src/basic.js
js">group('group', () => {
const str = '1234567890'
log(`str: ${str}`)
log(`str.match(/(123)*/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">(123)*regex-delimiter">/))
log(`str.match(/(123|456)*/):`, str.match(regex">regex-delimiter">/regex-source language-regex">(123|456)*regex-delimiter">/))
})

match 方法所返回的数组实际上就是匹配字符串的数组,第一个(下标 0)永远表示匹配表达式的整个字符串,而后面则接着由 () 中间的表达式所匹配的字符串序列,如上例子中 456 就是该组的最后一个匹配字符串
2.4 量词:?、+、*
我们能够匹配单个字符、特殊字符匹配指定字符集合、自定义字符集合之外,对于一些重复出现的逻辑或表达式我们则可以使用所谓的 量词 来重复,就不用一直重复复制粘贴
| 量词 | 含义 |
|---|---|
? | 0 个或 1 个(可存在也可不存在) |
* | 0 个到多个(可不存在) |
+ | 1 个到多个 |
{X} | X 个 |
{X,Y} | X 个到 Y 个( X ≤ n ≤ Y X \le n \le Y X≤n≤Y 为闭区间) |
{X,} | X 个到多个 |
注意这里提到的"多个"是指可以任意多个,在默认情况下开启所谓的 贪婪模式,也就是在尽量符合表达式的条件下,尽可能匹配多个字符。后面在进阶的章节我们会再讨论如何关闭贪婪模式
/src/basic.js
js">group('measure', () => {
const str = '1234567890'
log(`str: ${str}`)
log(`str.match(/\\d/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\dregex-delimiter">/))
log(`str.match(/\\d+/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d+regex-delimiter">/))
log(`str.match(/\\d*/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d*regex-delimiter">/))
log(`str.match(/\\d?/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d?regex-delimiter">/))
log(`str.match(/\\d{3}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d{3}regex-delimiter">/))
log(`str.match(/\\d{3,5}/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\d{3,5}regex-delimiter">/))
log(`str.match(/\\d{3,}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d{3,}regex-delimiter">/))
log(`str.match(/\\d{3}$/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d{3}$regex-delimiter">/))
log(`str.match(/^\\d{3}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">^\d{3}regex-delimiter">/))
})
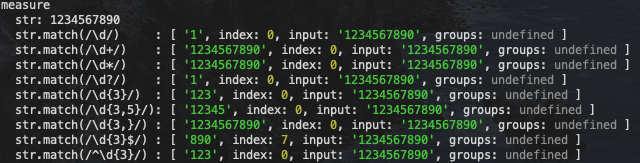
我们可以看到上述例子中都是尽可能匹配更多的数字字符,也就说明默认情况下的贪婪模式使用
2.5 修饰符:i、m、g
我们在前面提过,正则表达式的表示除了表达式本身之外(pattern),还存在所谓的 匹配模式 (modifier),在 JS 中支持的模式如下
| 模式 | 含义 |
|---|---|
i | ignore,表示忽略大小写的差异 |
m | multiline,表示多行匹配(也就是对于 ^、$ 字符匹配的不只是字符串的头尾,也可以是用 \n 区隔开来之后行内的头尾) |
g | global,表示全局匹配,也就是一次匹配所有符合表达式的字符串 |
/src/basic.js
js">group('modifiers', () => {
const str = '0123456789\nabcdeABCDE'
log(`str: ${str}`)
log(`str.match(/\\d{3}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d{3}regex-delimiter">/))
log(`str.match(/\\d{3}/g) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d{3}regex-delimiter">/regex-flags">g))
log(`str.match(/[a-z]{2}/g) :`, str.match(regex">regex-delimiter">/regex-source language-regex">[a-z]{2}regex-delimiter">/regex-flags">g))
log(`str.match(/[a-z]{2}/gi):`, str.match(regex">regex-delimiter">/regex-source language-regex">[a-z]{2}regex-delimiter">/regex-flags">gi))
log(`str.match(/^[a-z]+/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">^[a-z]+regex-delimiter">/))
log(`str.match(/^[a-z]+/m) :`, str.match(regex">regex-delimiter">/regex-source language-regex">^[a-z]+regex-delimiter">/regex-flags">m))
})
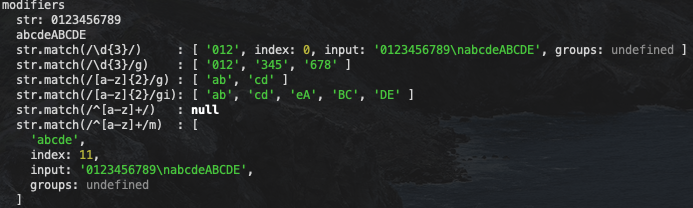
我们可以看到使用 i 的时候,表达式与原字符串的大小写会被忽略;使用 g 的时候会一次返回所有符合表达式的字符串数组(前面也提到过了);使用 m 的时候,作为第二行开头而不是字符串开头的 abcde 就能够被匹配到了
3. 正则表达值进阶
前面我们已经介绍完正则表达式的基础能力了,但是正则表达式的威力远远不止如此,下面我们来看看更进阶、更复杂的正则表达式符号的含义和用法。
3.1 反向引用
第一个是反向引用,我们前面提过 () 包起来的内容是一个组,这时候如果我们需要根据前面字符串匹配的内容来匹配后续的字符串的话我们就可以使用 反向引用
这样说有点抽象,现在假设我们要匹配的字符串如下
<div></div>
我们知道 html 标签一定有一个开始标签,一个结束标签,而两个标签的标签名应该一样,如果我们的表达式这样写
js">regex">regex-delimiter">/regex-source language-regex"><\w+><\/\w+>regex-delimiter">/ // \/ 表示转义的 / 字符
实际上前后两个标签的标签名是独立的,也就是说实际上下列字符串都符合上述表达式的描述
<div></span>
<tr></td>
<text></view>
然而这并不是我们想要的,我们想要制定结束标签中的名字应该要与开始标签匹配。这时候我们就可以将第一个标签的名字划分为一个"组",而结束标签则是引用这个组即可
| 符号 | 含义 |
|---|---|
\X | 表示匹配第 X 组所匹配的字符 |
接下来我们看看实际应用
/src/advance.js
js">group('reverse reference', () => {
const html = '<div></div>'
const tagPattern = regex">regex-delimiter">/regex-source language-regex"><(\w+)><\/\1>regex-delimiter">/
log(`html :`, html)
log(`tagPattern :`, tagPattern)
log(`html.match(tagPattern):`, html.match(tagPattern))
})
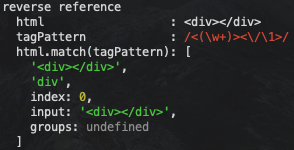
我们看到我们在结束标签中使用 \1 表示表达式的第一个匹配组,也就是 (\w+) 所匹配到的 div 字符串
3.2 贪婪模式 & 非贪婪模式
在前面我们提过所谓的量词默认情况下是 “贪婪” 的,也就是会尽可能匹配多个字符,但是有的时候我们会希望他尽可能的匹配少的字符,也就是说 在后续表达式匹配字符串出现的时候,立马结束当前贪婪匹配
使用的方法就是在所有量词后面多附带一个 ?
| 表达式符号 | 含义 |
|---|---|
+? | 非贪婪 + |
*? | 非贪婪 * |
{X,Y}? | 非贪婪 {X,Y} |
/src/advance.js
js">group('non-greedy', () => {
const str = 'abcde1234567890'
log(`str:`, str)
log(`str.match(/\\d+\\d{5}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d+\d{5}regex-delimiter">/))
log(`str.match(/\\d+?\\d{5}/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\d+?\d{5}regex-delimiter">/))
log(`str.match(/\\d*\\d{5}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d*\d{5}regex-delimiter">/))
log(`str.match(/\\d*?\\d{5}/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\d*?\d{5}regex-delimiter">/))
log(`str.match(/\\d?\\d{5}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">\d?\d{5}regex-delimiter">/))
log(`str.match(/\\d??\\d{5}/):`, str.match(regex">regex-delimiter">/regex-source language-regex">\d??\d{5}regex-delimiter">/))
log(`str.match(/[a-z]+\\d{5}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">[a-z]+\d{5}regex-delimiter">/))
log(`str.match(/[a-z]+?\\d{5}/):`, str.match(regex">regex-delimiter">/regex-source language-regex">[a-z]+?\d{5}regex-delimiter">/))
log(`str.match(/[a-z]*\\d{5}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">[a-z]*\d{5}regex-delimiter">/))
log(`str.match(/[a-z]*?\\d{5}/):`, str.match(regex">regex-delimiter">/regex-source language-regex">[a-z]*?\d{5}regex-delimiter">/))
log(`str.match(/[a-z]?\\d{5}/) :`, str.match(regex">regex-delimiter">/regex-source language-regex">[a-z]?\d{5}regex-delimiter">/))
log(`str.match(/[a-z]??\\d{5}/):`, str.match(regex">regex-delimiter">/regex-source language-regex">[a-z]??\d{5}regex-delimiter">/))
})
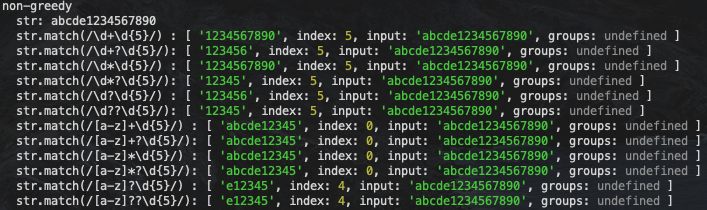
我们可以看到在 1、3、5、7、9、11 的例子中,前半部分都是尽量匹配更多的字符,在加上 ? 符号之后,则会在符合原本表达式的情况下,匹配满足表达式的最小字符串
3.3 非捕获组
这边我们又要在提起 () 所定义的捕获组。之所以称呼它为捕获组,实际上 JS 会为每个捕获组保留匹配子串(保存在内存中),然后在 match 方法的结果中返回。
但是有时候我们使用 () 不是为了捕获特定组合,而是用作 (|) 或是其他特别用途,没有特别想要留下匹配组,这时候我们就需要用到非捕获组,用法如下
| 表达式 | 含义 |
|---|---|
(?:abc) | 非捕获版本的以 abc 字符串为一组 |
/src/advance.js
js">group('uncaught', () => {
const string = '1234567890'
log(`string:`, string)
const caughtPattern = regex">regex-delimiter">/regex-source language-regex">(\d{3})\d{3}regex-delimiter">/
log(`caughtPattern :`, caughtPattern)
log(`string.match(caughtPattern):`, string.match(caughtPattern))
const uncaughtPattern = regex">regex-delimiter">/regex-source language-regex">(?:\d{3})\d{3}regex-delimiter">/
log(`uncaughtPattern :`, uncaughtPattern)
log(`string.match(uncaughtPattern):`, string.match(uncaughtPattern))
})

我们可以看到,第一个表达式匹配过后,第一个 (\d{3}) 匹配的 123 会被捕获并作为 match 方法的第二个参数返回(第一个捕获组);而第二个例子使用 (?:) 之后,就不会再捕获该组匹配的字符串了
3.4 先行匹配组(look-ahead)
非捕获组不仅仅只有 (?:) 一种用法,还有所谓的 先行匹配组(look-ahead)和后行匹配组(look-behind),我们先来看看什么是所谓的先行匹配组
我们知道正则表达式的匹配应该是由左至右进行匹配,但是有时候我们仅仅只是希望匹配目标字符串的前后应该呈现的模样,而不需要将前后的字符串纳入 0 捕获组(完整匹配字符串)当中,这时候我们就可以用到所谓的 先/后行匹配组
| 表达式 | 含义 |
|---|---|
(?=xxx) | 先行匹配,即在目标位置发现 xxx 字符串后才会继续匹配后续的表达式 |
(?!xxx) | 先行非匹配,即目标位置不符合 xxx 时才继续匹配 |
/src/advance.js
js">group('look ahead assertion', () => {
const str = 'abcde12345fghij67890'
log(`str:`, str)
const uncaughtPattern = regex">regex-delimiter">/regex-source language-regex">[a-z]{5}(?:1)regex-delimiter">/
log(`uncaughtPattern :`, uncaughtPattern)
log(`str.match(uncaughtPattern):`, str.match(uncaughtPattern))
const positiveAssertionPattern = regex">regex-delimiter">/regex-source language-regex">[a-z]{5}(?=1)regex-delimiter">/
log(`positiveAssertionPattern :`, positiveAssertionPattern)
log(
`str.match(positiveAssertionPattern):`,
str.match(positiveAssertionPattern)
)
const negativeAssertionPattern = regex">regex-delimiter">/regex-source language-regex">[a-z]{5}(?!1)regex-delimiter">/
log(`negativeAssertionPattern :`, negativeAssertionPattern)
log(
`str.match(negativeAssertionPattern):`,
str.match(negativeAssertionPattern)
)
const negativeAssertionPattern2 = regex">regex-delimiter">/regex-source language-regex">[a-z]+(?!1)regex-delimiter">/
log(`negativeAssertionPattern2 :`, negativeAssertionPattern2)
log(
`str.match(negativeAssertionPattern2):`,
str.match(negativeAssertionPattern2)
)
})
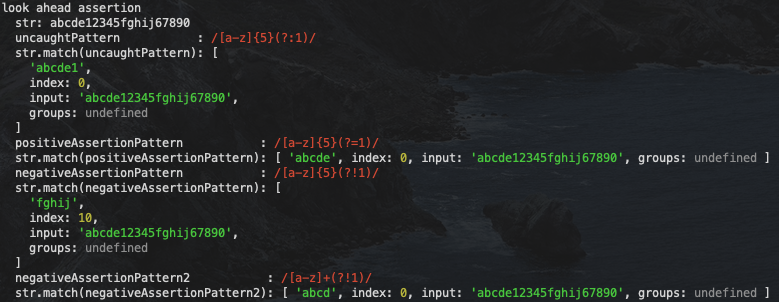
上述例子我们看到:
- 对于第一个例子:仅仅使用非捕获组
(?:),所以虽然没有保留独立的小组,但是还是将 1 匹配到字符串内容里面了 - 第二个例子:使用
(?=1)先行匹配 1,也就是说目标字符串的后面应该存在 1,但是这个 1 不应该被放入最终结果的匹配字符串当中 - 第三个例子;使用
(?!1)先行非匹配 1,所以后面不可以接 1,所以最终匹配到的串不是abcde而是fghij(因为abcde后面有 1)
3.5 后行匹配组(look-behind)
理解先行匹配组之后,后行匹配组就比较好理解了。
简单来说:先行匹配组 是匹配该组之后才会继续匹配后续表达式,而 后行匹配组 则是先匹配后续表达式之后,再回头匹配是否匹配该匹配组。语法上就是比先行匹配组多一个 < 符号
| 表达式 | 含义 |
|---|---|
(?<=xxx) | 后行匹配,即先匹配后续字符串,然后再检查匹配结果前面是否符合后行匹配组 |
(?<!xxx) | 后行非匹配,即匹配结果前不等于后行匹配组表达式的匹配 |
有点抽象,下面看看例子
/src/advance.js
js">group('look behind assertion', () => {
const str = 'abcde12345fghij67890'
log(`str:`, str)
const positiveLookAheadAssertionPattern = regex">regex-delimiter">/regex-source language-regex">(?=e)\d{5}regex-delimiter">/
log(
`positiveLookAheadAssertionPattern :`,
positiveLookAheadAssertionPattern
)
log(
`str.match(positiveLookAheadAssertionPattern):`,
str.match(positiveLookAheadAssertionPattern)
)
const positiveLookBehindAssertionPattern = regex">regex-delimiter">/regex-source language-regex">(?<=e)\d{5}regex-delimiter">/
log(
`positiveLookBehindAssertionPattern :`,
positiveLookBehindAssertionPattern
)
log(
`str.match(positiveLookBehindAssertionPattern):`,
str.match(positiveLookBehindAssertionPattern)
)
const negativeLookBehindAssertionPattern = regex">regex-delimiter">/regex-source language-regex">(?<!e)\d{5}regex-delimiter">/
log(
`negativeLookBehindAssertionPattern :`,
negativeLookBehindAssertionPattern
)
log(
`str.match(negativeLookBehindAssertionPattern):`,
str.match(negativeLookBehindAssertionPattern)
)
})
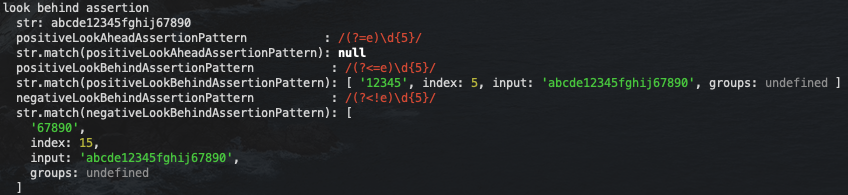
我们看到,第一个例子使用了先行匹配组,所以我们发现因为字符串本身就不符合 e,所以直接不去匹配剩余的部分
第二个例子则是使用了后行匹配组,也就是先去寻找 \d{5} 的部分,然后再检查是否满足前面带有 e 的字符串(注意这里的 e 也跟非捕获组一样,不会被放入匹配结果字符串里面)
第三个例子则是后行非匹配的例子
3.6 先行 & 后行
整体来说先行/后行匹配组就好像测试的时候用的 before 跟 after 有点像:
- 只有当满足
before的时候才会执行剩下的匹配 - 而匹配结束之后只有满足
after的会留下
4. 正则表达式的应用
最后的最后我们看看几个正则表达式的应用
正则表达式的应用几乎都离不开字符串的验证、字符串的解析,所以我们就举三个例子
4.1 简单匹配:字符串格式匹配(匹配邮箱)
第一个是匹配邮箱的正则表达式,实际上这就是一种字符串格式的验证
/src/application.js
js">group('application: mail address', () => {
const mail = 'superfreeeee@gmail.com'
const mailPattern = regex">regex-delimiter">/regex-source language-regex">[_\w]+@(?:\w+\.)[a-z]+regex-delimiter">/
log('mail :', mail)
log('mailPattern :', mailPattern)
log(`mail.match(mailPattern):`, mail.match(mailPattern))
})
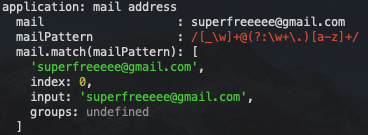
这里使用 match 方法就是方便大家观察匹配结果而已,实际上我们就可以将上面的代码改成使用 test 方法,然后包装成一个用于验证字符串格式的方法:
js">function isMailAddress(addr) {
const mailPattern = regex">regex-delimiter">/regex-source language-regex">[_\w]+@(?:\w+\.)[a-z]+regex-delimiter">/
return mailPattern.test(addr)
}
4.2 字符串解析 1:解析 URL
第二个我们要来解析 URL 字符串,之前在 一次搞懂 URI、URL、URN 提过,URL 的格式应该如下
[协议类型]://[服务器位置IP]:[端口]/[资源层级路径][资源名称]?[查询参数]#[片段ID]
这时候我们就可以使用正则表达式将每个部分切割下来
/src/application.js
首先我们可以先用第一个表达式将查询参数分离出来
js">group('application: url parse', () => {
const url1 =
'http://localhost:8080/user/login?name=superfree&mail=superfreeeee@gmail.com'
const urlPattern = regex">regex-delimiter">/regex-source language-regex">(http|https):\/\/(\w+):(\d+)((?:\/\w+)*)(\?.*)regex-delimiter">/
log('url1 :', url1)
log('urlPattern :', urlPattern)
log(`url1.match(urlPattern):`, url1.match(urlPattern))
接下来我们用第二个表达式 g 标识符与 match 方法连用来流式处理多个查询参数
js"> const queryParamsPattern = regex">regex-delimiter">/regex-source language-regex">([^?&#+]+=[^?&#+]+)regex-delimiter">/regex-flags">g
group('match query parameters', () => {
log('queryStr :', queryStr)
log('queryParamsPattern :', queryParamsPattern)
log(
`queryStr.match(queryParamsPattern):`,
queryStr.match(queryParamsPattern)
)
})
最后我们就可以封装成一个函数 parseUrl,返回解析后的 URL 描述对象:
js"> function parseUrl(url) {
const urlPattern = regex">regex-delimiter">/regex-source language-regex">(http|https):\/\/(\w+):(\d+)((?:\/\w+)*)(\?.*)regex-delimiter">/
const queryParamsPattern = regex">regex-delimiter">/regex-source language-regex">([^?&#+]+=[^?&#+]+)regex-delimiter">/regex-flags">g
const [, protocal, host, port, path, queryStr] = url.match(urlPattern)
const props = {}
queryStr.match(queryParamsPattern).forEach((pair) => {
const [key, value] = pair.split('=')
props[key] = value
})
return {
protocal,
host,
port,
path,
props,
}
}
log('parseUrl(url1):', parseUrl(url1))
})
最终结果如下
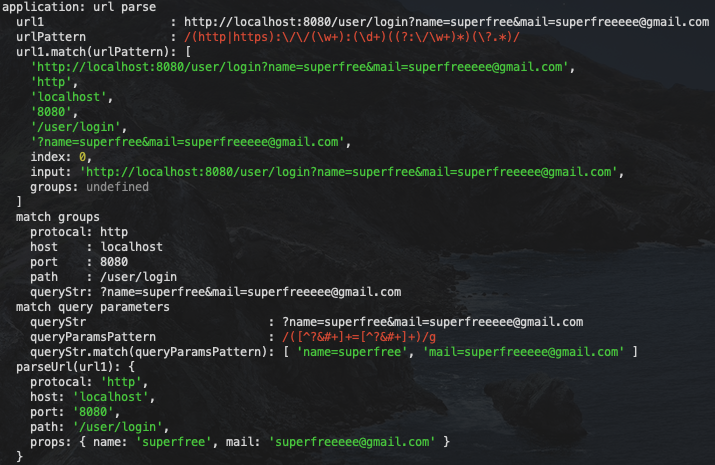
4.3 字符串解析 2:解析 HTML
最后一个比较复杂,是之前在解析 Vue 源码的时候,在模版编译的部分看到的(有兴趣这里有链接 → \to → Vue2 源码解析: MVVM 双向绑定3 - 模版编译实现)
第三个例子我们就模仿 Vue 来写一个 HTML 模版解析器
/src/application.js
首先是我们要解析的目标字符串
js">group('application: html', () => {
let html = `<div id="root" class="container" style="width: 100px; height: 200px">
<h1>这是一个标题</h1>
<br/>
<p>这是一个段落</p>
</div>`
4.3.1 解析开始标签
接下来先给出几个匹配函数,第一个是关于开始标签的检查与解析
js"> function isStartTag(html) {
return regex">regex-delimiter">/regex-source language-regex">^<[^\/]regex-delimiter">/.test(html)
}
function parseStartTag(html) {
let matcher
// parse tag name: <tagName
const startTagPattern = regex">regex-delimiter">/regex-source language-regex">^<(\w+)regex-delimiter">/
matcher = html.match(startTagPattern)
const [parsed, tagName] = matcher
html = html.substring(matcher.index + parsed.length).trim()
// parse attrs: xxx="xxx"
const attrPattern = regex">regex-delimiter">/regex-source language-regex">^(\w+)="(.*?)"regex-delimiter">/
const attrs = {}
while ((matcher = attrPattern.exec(html))) {
const [parsed, key, value] = matcher
attrs[key] = value
html = html.substring(matcher.index + parsed.length).trim()
}
// parse end of start tag: >
let index,
closed = false
index = html.search(regex">regex-delimiter">/regex-source language-regex">^\/>regex-delimiter">/)
if (index >= 0) {
closed = true
html = html.substring(index + 2).trim()
} else {
index = html.search(regex">regex-delimiter">/regex-source language-regex">>regex-delimiter">/)
html = html.substring(index + 1).trim()
}
return [{ tagName, attrs, children: [], closed }, html]
}
isStartTag 方法会检查是否符合 <xxx 的形式;而 parseStartTag 则会返回一个形如 { tagName, attrs, children, closed } 的对象,各个属性含义如下
tagName标签名称attrs属性键值对children子元素数组closed是否为自闭合标签
4.3.2 匹配结束标签
除了开始标签之外,我们还要匹配结束标签
js"> function isEndTag(html) {
return regex">regex-delimiter">/regex-source language-regex">^<\/regex-delimiter">/.test(html)
}
function parseEndTag(html) {
const endTagPattern = regex">regex-delimiter">/regex-source language-regex">^<\/(\w+)>regex-delimiter">/
const matcher = html.match(endTagPattern)
const [parsed, tagName] = matcher
return [{ tagName }, html.substring(matcher.index + parsed.length).trim()]
}
这里 parseEndTag 返回的对象比较简单,就只有结束标签名而已
4.3.3 匹配文本标签
除了开始标签和文本标签之外,我们将其他一切内容都视为文本处理
js"> function parseText(html) {
let index = html.search('<')
if (index < 0) index = html.length
const text = html.substring(0, index)
return [text, html.substring(index)]
}
我们将下一个 < 符号的出现或是 html 字符串的结尾作为文本内容的结束点,然后直接返回文本内容 text
4.3.4 标签栈结构
在开始循环匹配之前,我们先建立一个用于保存开始标签的栈
js"> const nodes = []
const stack = []
当我们遇到任何尚未闭合的开始标签的时候就压入栈中,遇到结束标签的时候就就闭合栈上的最后一个标签,并加入作为新的栈定元素的子元素
js"> function closeTag(matcher) {
if (stack.length) {
stack[stack.length - 1].children.push(matcher)
} else {
nodes.push(matcher)
}
}
4.3.5 循环匹配 & 解析
我们定义好匹配开始标签、匹配结束标签、匹配文本、标签栈结构之后,终于可以来开始正式的循环匹配 html 内容了
js"> while (html) {
const lastHtml = html
// parse start tag
if (isStartTag(html)) {
const [matcher, restHtml] = parseStartTag(html)
if (!matcher.closed) {
stack.push(matcher)
} else {
closeTag(matcher)
}
html = restHtml
continue
}
// parse end tag
if (isEndTag(html)) {
const [matcher, restHtml] = parseEndTag(html)
let lastTag
while ((lastTag = getLastTag())) {
if (matcher.tagName !== lastTag.tagName) {
log(
`unmatched tag: ${lastTag.tagName}, expected: ${matcher.tagName}`
)
stack.pop()
closeTag(lastTag)
} else {
break
}
}
stack.pop()
closeTag(lastTag)
html = restHtml
continue
}
// parse text
const [text, restHtml] = parseText(html)
if (text) {
getLastTag().children.push(text)
html = restHtml
}
if (html === lastHtml) break
}
整个 while 循环分成三个段落:
- 匹配开始标签
js"> // parse start tag
if (isStartTag(html)) {
const [matcher, restHtml] = parseStartTag(html)
if (!matcher.closed) {
stack.push(matcher)
} else {
closeTag(matcher)
}
html = restHtml
continue
}
- 匹配结束标签
js"> // parse end tag
if (isEndTag(html)) {
const [matcher, restHtml] = parseEndTag(html)
let lastTag
while ((lastTag = getLastTag())) {
if (matcher.tagName !== lastTag.tagName) {
log(
`unmatched tag: ${lastTag.tagName}, expected: ${matcher.tagName}`
)
stack.pop()
closeTag(lastTag)
} else {
break
}
}
stack.pop()
closeTag(lastTag)
html = restHtml
continue
}
- 匹配文本
js"> // parse text
const [text, restHtml] = parseText(html)
if (text) {
getLastTag().children.push(text)
html = restHtml
}
4.3.6 解析成果
详细的运行细节就不展开说明了,有兴趣的可以细看一下。最后给出运行结果
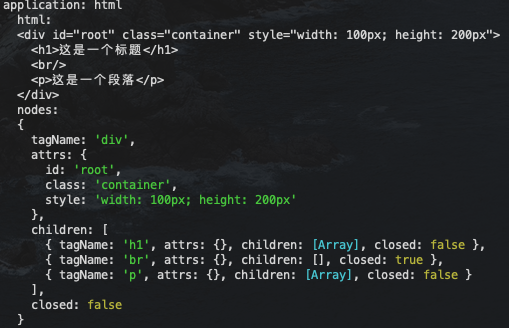
结语
正则表达式在字符串处理中扮演重要的地位,它强大的表达能力能够为我们省去极大的代码开销,所以不要再用 index 一个个字符去读了!
本篇提到的主要是正则表达式的基础符号以及含义,具体的应用还是要读者自己慢慢实践会更深有体会!供大家参考~
其他资源
参考连接
| Title | Link |
|---|---|
| RegExr 正则表达式学习、测试平台 | https://regexr.com/ |
| [Python] re正则表达式指南以及常用操作 | https://www.cnblogs.com/bymo/p/7481583.html |
| JavaScript RegExp 对象 - 菜鸟教程 | https://www.runoob.com/jsref/jsref-obj-regexp.html |
| JavaScript RegExp 参考手册 - w3school | https://www.w3school.com.cn/jsref/jsref_obj_regexp.asp |
| JavaScript RegExp m 修饰符 | https://www.jc2182.com/javascript/javascript-regexp-m-modify.html |
| 正则表达式高级用法(分组与捕获) | https://www.cnblogs.com/cangqinglang/p/11152733.html |
| 正则表达式中的反向引用 | https://blog.csdn.net/raoshihong/article/details/17004641 |
| 正则表达式之 贪婪与非贪婪模式详解(概述) | https://www.cnblogs.com/admans/p/11955614.html |
| 手写js模板编译器 | https://blog.csdn.net/brokenkay/article/details/114198027 |
完整代码示例
https://github.com/superfreeeee/Blog-code/tree/main/front_end/javascript/js_regexp