一、前言
scrapy是基于twisted的异步处理框架,与传统的requests爬虫程序执行流程不同,scrapy使用多线程,将发送请求,提取数据,保存数据等操作分别交给Scheduler(调度器),Downloader(下载器),Spider(爬虫),Pipeline(管道)等爬虫“组件”来完成。多线程的运行框架使得爬虫的效率大大提升,让爬虫程序变得更快,更强。基于以上特点,本文将以爬取豆瓣图书信息为例,简要阐述基于scrapy框架下的爬虫实现流程。
二、爬虫流程以及代码实现
(一)分析需要爬取的网页结构
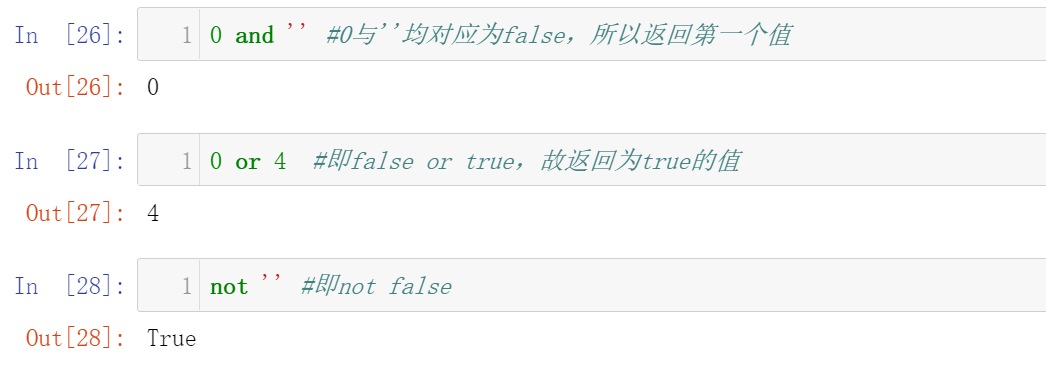
在编写一个爬虫项目之前,我们需要对所需爬取的网页有一个清晰的认识。爬虫的本质是在响应中的字符串提取所需信息,即只有我们提取到的响应中存在我们所需要的数据时,我们才能进行爬虫。我们访问豆瓣读书,发现豆瓣图书标签中存在许多大分类(文学,文化...),大分类中存在许多小分类(小说,外国文学...)。点开每个小分类标签,会呈现出不同类型的书的列表清单,且不止一页。我们要做的就是提取豆瓣所有类型书籍下的所有书籍的简要信息,包括图书作者,书名,图书价格,豆瓣评分,书籍评论人数等。网页的页面如下图所示:

图1.豆瓣的图书标签页
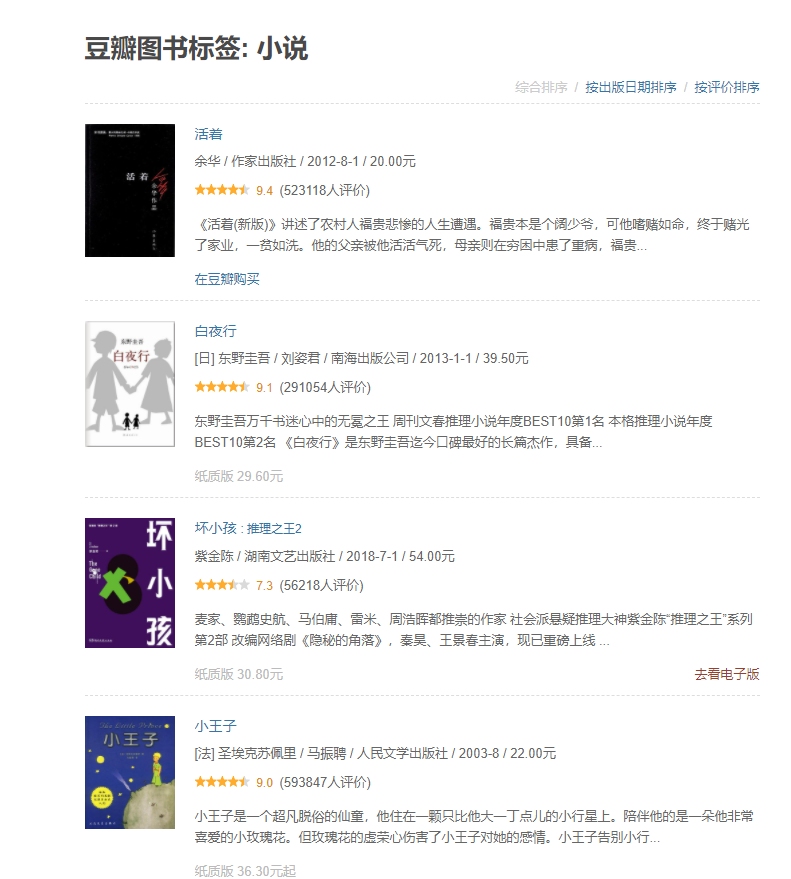
图2.豆瓣每个小标签下的url页面
(二)创建scrapy项目
创建scrapy项目十分简单,首先打开命令提示符,通过cd命令路径,将工作路径定位到我们需要创建项目的路径下,然后创建一个scrapy项目,用到的程序如下:
scrapy startproject douban_books #创建一个名字为douban_books的爬虫项目
cd douban_books #定位到项目文件夹内
scrapy genspider book book.douban.com #创建爬虫所需的脚本文件book.py;book.douban.com设置允许爬取的网页范围(allow_domains)
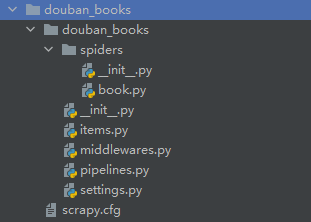
图3.scrapy项目内容显示
(三)设置USER_AGENT,LOG_LEVEL
接下来我们切换到settings.py文件中,对爬虫项目进行变量配置与赋值。首先,利用url地址请求头中的USER_AGENT对发送请求进行伪装,可更加顺利地发送请求并获取到服务器的响应。用LOG_LEVEL设置日志级别,让打印出来的结果更加干净,整洁。
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' #设置useragent
LOG_LEVEL = 'WARNING' #设置日志级别,即输出结果只会显示warning以及warning以上的日志
(四)编写爬虫程序
打开spiders文件夹下的book.py文件,我们将在此文件中编写实现提取数据的核心代码。
在此程序中,start_url为我们首先要发送的url地址,该url地址不受allowed_domains约束;parse函数用来执行提取start_url页面数据的主要逻辑,需要注意,该函数名不可以随意更改。如下:
import scrapy
import re
from copy import deepcopy
class BookSpider(scrapy.Spider):
name = 'book'#爬虫名
allowed_domains = ['book.douban.com'] #允许爬取的url地址范围
start_urls = ['https://book.douban.com/tag/?view=type'] #首先发送请求的url地址
def parse(self, response): #实现提取数据等主要逻辑
pass
程序的基本框架搭建好后,就可以开始编写获取网页信息的程序。
1. 提取豆瓣图书的大标签,小标签
在开发者工具的elements界面,可以通过对网页的观察定位到所需信息的xpath并进行相应提取。此外,大家也可使用爬虫利器xpath helper进行定位。
通过网页标签分析可以看出,大标题(小说,外国文学...)对应了六块大标签,每块大标签下存放了以行捆绑的中标签,中标签下才是我们所需要提取的小标签(文学,文化...)。因此想要提取到所有数据,我们需要对响应进行三次遍历操作。
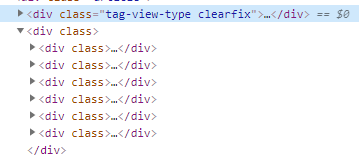
图4.该6个div标签下存放有标签数据
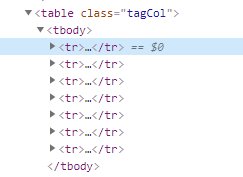
图5.每个小便签按照每一行进行分组
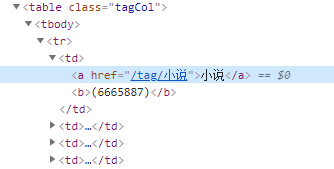
图6.每个td小标签下有我们所需要的标签数据和详情页地址
def parse(self, response):
item = {}
div_list = response.xpath(".//div[@class='article']/div[2]/div") # 进行分组
for div in div_list:
item["big_title"] = div.xpath("./a/@name").extract_first() # 提取大标签
tr_list = div.xpath(".//table[@class='tagCol']") # 进行分组
for tr in tr_list:
td_list = tr.xpath(".//td")
for td in td_list:
item["small_title"] = td.xpath("./a/text()").extract_first()
item["cate_list_url"] = td.xpath("./a/@href").extract_first()
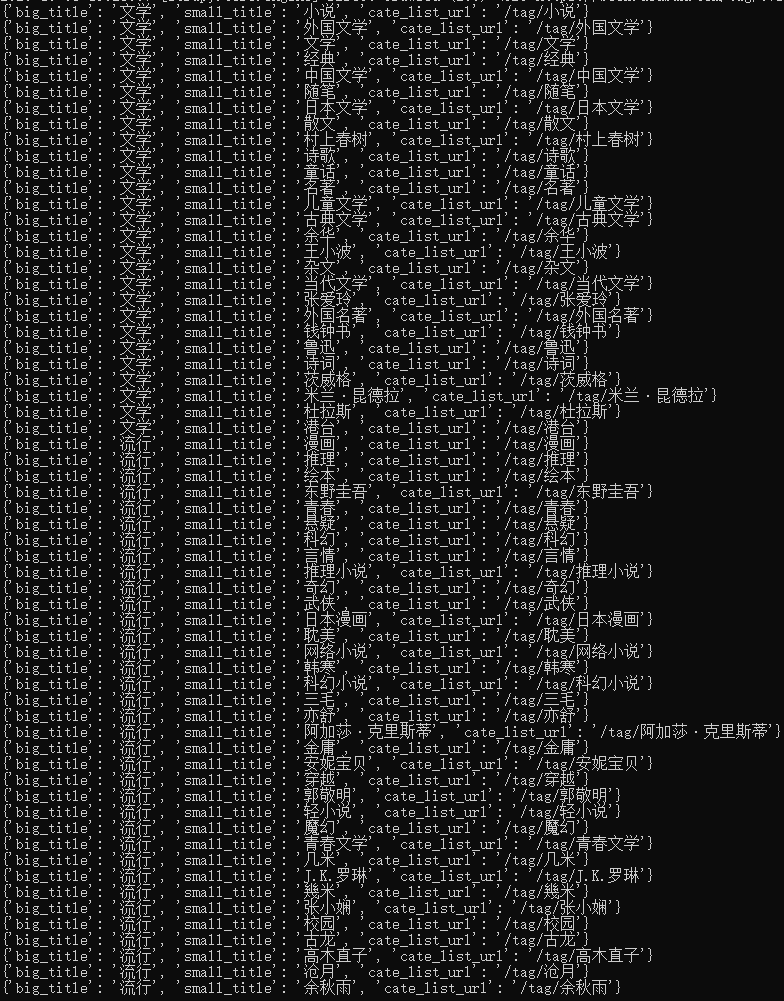
图7.我们所获取到的大标签、小标签以及对应的url地址
2.发送每个小标签地址的请求,获取每个小标签url地址的响应
从图7可以看出,我们抓取的url地址不完整,因此需要对其进行补充,再分别发送请求。
if item["cate_list_url"] is not None:
item["cate_list_url"] = 'https://book.douban.com' + item["cate_list_url"]
yield scrapy.Request(
item["cate_list_url"],
callback=self.parse_list,
meta={"item": deepcopy(item)}
)
3. 提取书籍的数据
在2节中我们获取了每个小标签url地址的响应,接下来只需要新定义一个函数parse_list来处理响应,就可以抓取到所需数据。而这些数据中往往带有换行符、制表符以及空格等我们所不需要的字符,因此可以使用正则表达式进行处理,使最终提取的数据更为美观。
def parse_list(self, response):
item = response.meta["item"]
li_list = response.xpath(".//ul[@class='subject-list']/li") # 分组
for li in li_list:
item["book_name"] = li.xpath(".//div[@class='info']/h2/a/@title").extract_first()
item["book_name"] = re.sub(r"[(\n)(\t)( )]", "", item["book_name"]) #删除书名中的空格与换行符等
item["book_score"] = li.xpath(".//div[@class='star clearfix']/span[@class='rating_nums']/text()").extract_first()
book_detail_str = li.xpath(".//div[@class='info']//div[@class='pub']/text()").extract_first()
book_detail_str = re.sub(r"[(\n)( )]", "", book_detail_str) #提取书籍简要信息,并对简要信息进行切片处理,提取切片中的内容
book_detail_list = list(book_detail_str.split("/"))
item["book_price"] = book_detail_list[-1] if len(book_detail_list) > 0 else None
item["book_author"] = book_detail_list[0] if len(book_detail_list) > 0 else None
item["book_comment_nums"] = li.xpath(".//div[@class='star clearfix']/span[@class='pl']/text()").extract_first()
item["book_comment_nums"] = re.sub(r"[(\n)( )]", "", item["book_comment_nums"])
print(item)
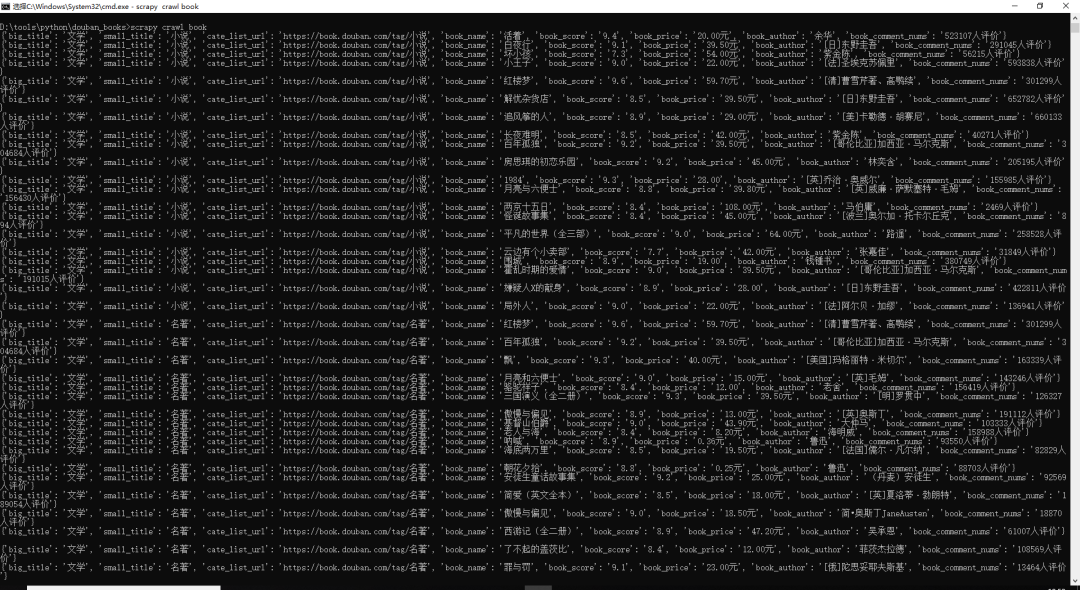
图8.数据简要预览
4.实现翻页请求
通过对网页结构进行分析,小编发现每一个小便签下的图书信息不止一页,因此需要设置翻页请求,定位到“下一页”按钮标签后,同样发现抓取的url地址不全,需要将地址补全。小编将发出翻页请求所对应的响应(即callback)也放入parse_list函数。
图9.每一页数据爬取完毕需对下一页进行请求
next_page = response.xpath(".//span[@class='next']/a/@href").extract_first()#提取url地址
if next_page is not None:#判断,如果还有下一页,就继续发送请求
next_page = 'https://book.douban.com' + next_page
yield scrapy.Request(
next_page,
callback=self.parse_list,#把发出的请求交给parse_list函数进行处理
meta = {"item":deepcopy(item)}
)
yield item
5. 开启管道,保存数据
管道用于将爬取的数据保存到本地文件或数据库中。管道需要事先在settings.py文件中开启,将# Configure item pipelines下的注释行解除,便可在pipeline.py中实现保存功能,本文以创建一个.txt文档对数据进行保存为例。
import json
class DoubanBooksPipeline:
def process_item(self, item, spider):
with open("douban_book_list.txt","a",encoding="utf-8") as f:
f.write(json.dumps(item,ensure_ascii=False))
6. 运行项目,爬取数据
完成上述设置后,就可运行项目抓取数据啦。运行项目仅需打开命令提示符,输入如下程序即可执行:
scrapy crawl book
三、注意事项
1.deepcopy是用于不同函数在多线程传输之中进行备份操作的行为。由于数据公用一个item字典,在多线程操作中可能出现重复值的现象,利用deepcopy可以有效地解决item中出现重复值的问题。
2.豆瓣具备一定反爬虫,scrapy可能用同一个headers运行数秒就会被服务器监测为爬虫行为,需要利用一些反反爬虫的操作。例如:在settings.py中设置一个USER_AGENT和IP池,并在发送请求时随机选择一个USER_AGENT和IP,便可以进行有效地伪装,达到更完善的爬虫效果。
(ps:要免费领取资料的加QQ2931934545,或加微dingyu-003领取更多资料,备注999领取)